STSA: Spatial-Temporal Semantic Alignment for Visual Dubbing
Zijun Ding, Mingdie Xiong, Congcong Zhu*, Jingrun Chen
原文链接:https://arxiv.org/abs/2503.23039
开源代码:https://github.com/SCAILab-USTC/STSA
实验室具身智能方向2024级硕士研究生丁子骏同学的最新工作《STSA:Spatial-Temporal Semantic Alignment for Visual Dubbing》发表在CCF-B类推荐会议ICME 2025,该工作致力于解决音频驱动的视觉配音(Audio-Driven Visual Dubbing)在动态人脸合成中的语义模糊与稳定性问题。现有的模型往往只在空间域或时间域上对特征形变,导致时空域上的语义模糊;此外,现有的模型通常使用不可微分、像素级别的关键点或关键点连线图作为中间语义表征,导致两阶段生成中的误差累计,加剧了时空域上的不稳定性。
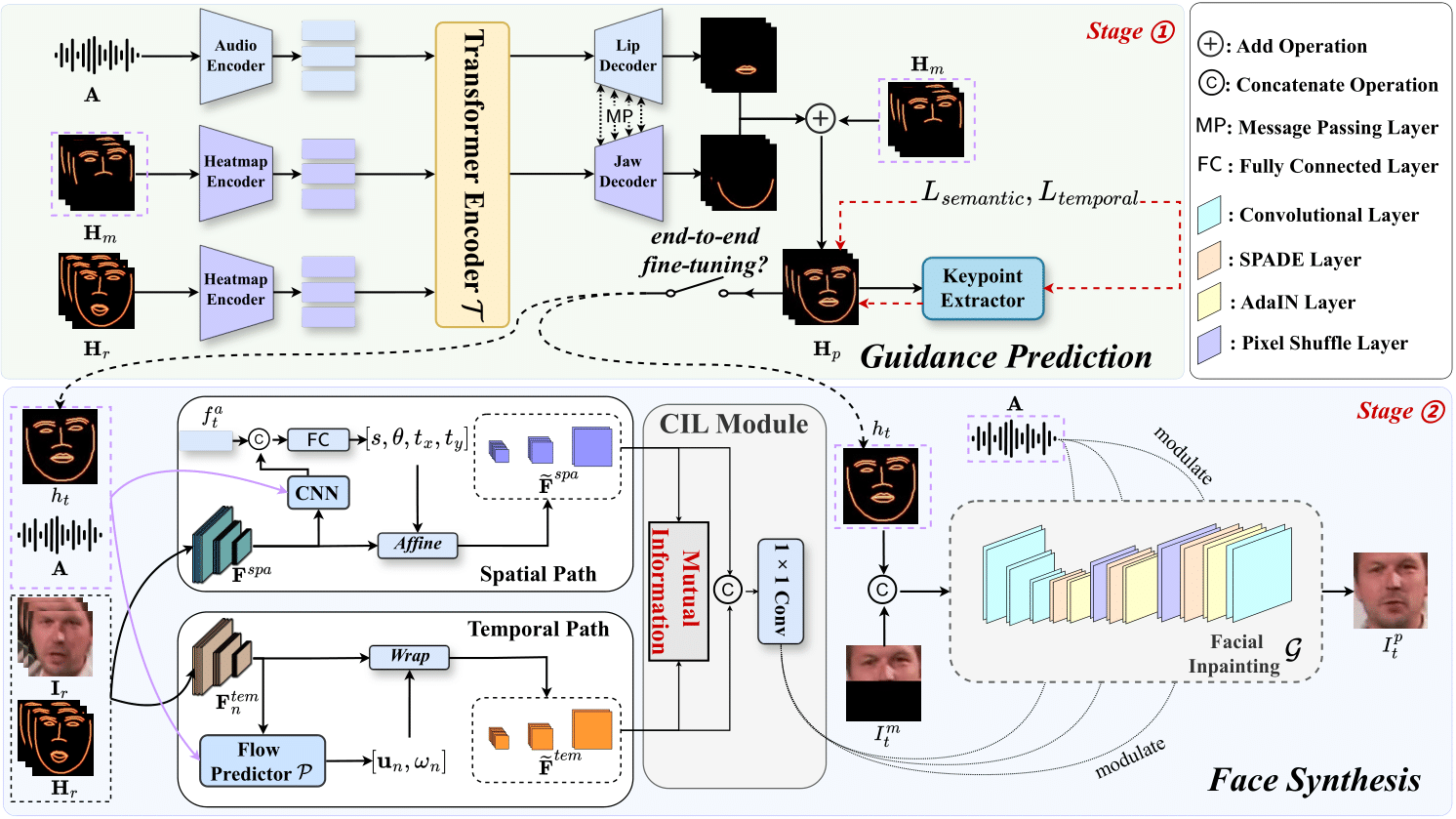
图1. 模型架构图
本研究提出了一种创新的模型框架,对中间特征进行了时空语义对齐,减少了语义模糊并实现了真实且稳定的视觉配音。首先,设计的双路对齐机制利用一致信息学习模块(CIL Module)最大化空间域和时间域的互信息量来实现双域特征对齐。除此之外,模型引入概率热力图作为模糊可容忍的中间语义表征,以增强合成动作的平滑性。实验结果表明了本文提出模型的先进性,尤其在图像质量和合成稳定性方面。
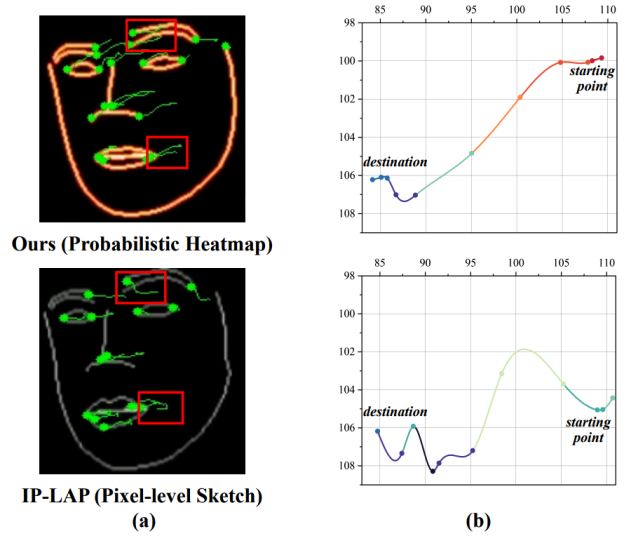
图2. 中间表征运动轨迹的对比